카테고리 없음
Spark의 핵심 데이터 모델 정리 (RDD, Dataframe, Dataet)
0hyeon의
2025. 5. 25. 03:17
반응형
Spark의 핵심 데이터 모델 정리

1. RDD (Resilient Distributed Dataset)
RDD는 Spark의 가장 기본적인 분산 데이터 모델로, MapReduce보다 더 유연하고 빠르게 데이터를 처리할 수 있게 해준다.
핵심 특징
- Resilient (탄력성): 오류가 발생해도 데이터를 복구할 수 있는 fault-tolerant 구조
- Distributed (분산): 여러 노드에 데이터를 나눠 저장하고 처리함
- Dataset (불변성): 한 번 생성되면 변경되지 않으며, 항상 새로운 RDD를 반환 (함수형 방식)
MapReduce와 비교
- 유사한 분산 처리 모델이지만, 메모리 중심의 연산으로 훨씬 빠름
- MapReduce가 디스크 기반이라면, RDD는 메모리를 적극 활용
- MapReduce는 "무엇을 할지" 표현하고, RDD는 "어떻게 처리할지" 더 세세히 제어 가능
RDD의 복구 메커니즘: Lineage
- 모든 Transformation은 **DAG (Directed Acyclic Graph)**로 구성됨
- DAG를 통해 연산 흐름을 추적하고, 중간 RDD가 손실되면 이전 단계를 따라 재계산 가능
연산의 종류
Transformation (변환)
- Lazy Evaluation: 실제 실행은 Action이 호출될 때까지 지연됨
- 기존 RDD를 바탕으로 새로운 RDD를 생성
- 대표 함수:
- map(): 각 요소에 함수 적용 → 새로운 RDD
- filter(): 조건을 만족하는 요소만 추출
- union(): 두 RDD의 합집합
- distinct(): 중복 제거
Action (행동)
- 실제로 결과를 반환하거나 외부에 출력하는 작업
- 예시: collect(), count(), saveAsTextFile() 등
2. DataFrame(distributed collection of data organized into named columns)
Spark 데이터 처리속도 증가를 위해 등장 (텅스텐 프로젝트)
DataFrame은 RDD 위에 있는 고수준의 API로, SQL처럼 행과 열로 구성된 테이블 형태로 데이터를 다룰 수 있다.
그리고 다양한 포맷과 소스지원..

주요 특징
- 스키마(Schema)를 가진 구조화된 데이터
- Catalyst Optimizer를 통해 쿼리 최적화 가능
- Catalyst Optimizer : Spark SQL, DataFrame, Dataset API의 논리적 최적화 엔진
- 1. 분석 (Analysis)
- 테이블 스키마 확인
- 컬럼 타입 검사
- 잘못된 컬럼이나 함수 사용 잡아냄
- 2. 논리적 최적화 (Logical Optimization)
- 쿼리 내용을 최적화된 방식으로 바꿈
- 예: 중복 필터 제거, 쓸데없는 컬럼 제거 (Column Pruning), Pushdown 최적화 등 (쿼리에 필요한것만 사용)
- 3. 물리적 계획 생성 (Physical Planning)
- 실제 Spark가 사용할 연산자(예: SortMergeJoin vs BroadcastJoin)를 정함
- 상황에 따라 더 빠른 Join 방식으로 자동 교체
- 4. 실행 계획 선택 (Codegen 포함)
- 선택된 계획을 바탕으로 실제 코드(Java Bytecode)로 컴파일
- 이 단계에서 Tungsten 엔진이 함께 작동!
- 1. 분석 (Analysis)
- Catalyst Optimizer : Spark SQL, DataFrame, Dataset API의 논리적 최적화 엔진
- 표현은 SQL처럼, 실행은 분산환경에서 자동 최적화
- 생산적 : compoie-time type-safety -> 컴파일타임의 타입을 확신하여 에러가능성 낮춘다.
- easy to use: high-level functions -> sql베이스 쿼리사용할수있어 간편하다
- fast and optimized: catalyst code optimizer -> RDD보다 빠르고, 최적화
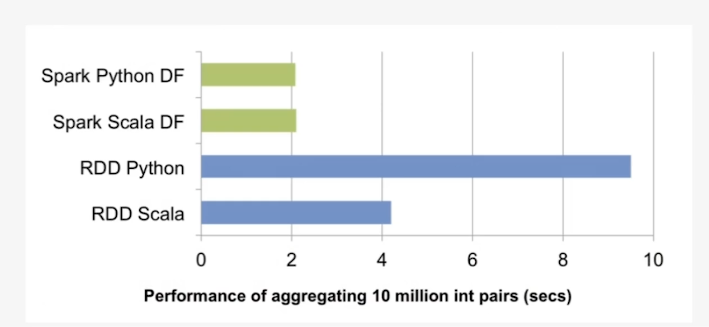
장점
- RDD보다 간결한 코드로 복잡한 연산 가능
- CSV, JSON, Hive 등 다양한 포맷의 데이터 연결이 쉬움
- .select(), .where(), .groupBy() 같은 SQL 유사 문법 제공
언제 DataFrame사용할까?
- Data requires a structure: infer a schema -> 데이터가 structure 존재할때, 스키마가 자동으로 inferencec(추론)함.
- high-level transformation: column functions. SQL queries -> 컬럼별로 column functions. SQL queries 사용하고싶을때
- type sfaety: Compile-time type-safety -> 컬럼별로 타입을 지정할수있기때문에 컴파일타임에 에러가 발생한다 해서 타입이 중요한경우
그럼 언제 RDD를 사용하나?
- low-level trnasformation and actions
- unstructured data ex) media stream or streams of text
- functions programming -> 값이 바뀌지않는 함수형 프로그래밍의 특성의 구현방법이 익숙한경우
- don't care abount imposing a schema -> 굳이 스키마 임포트 할필요없는경우
- don't need optimization and performance benefits available with DataFrames and Datasets for structed and semi-structured data -> 옵티마이퍼포먼스 베네핏 -> 거의없지만 옵티마이제이션, 퍼포먼스 베네핏이 필요없는경우
3. Dataset (Typed API)
Dataset은 DataFrame의 타입 안정성을 강화한 형태로, Java/Scala 사용자에게 유리하다.
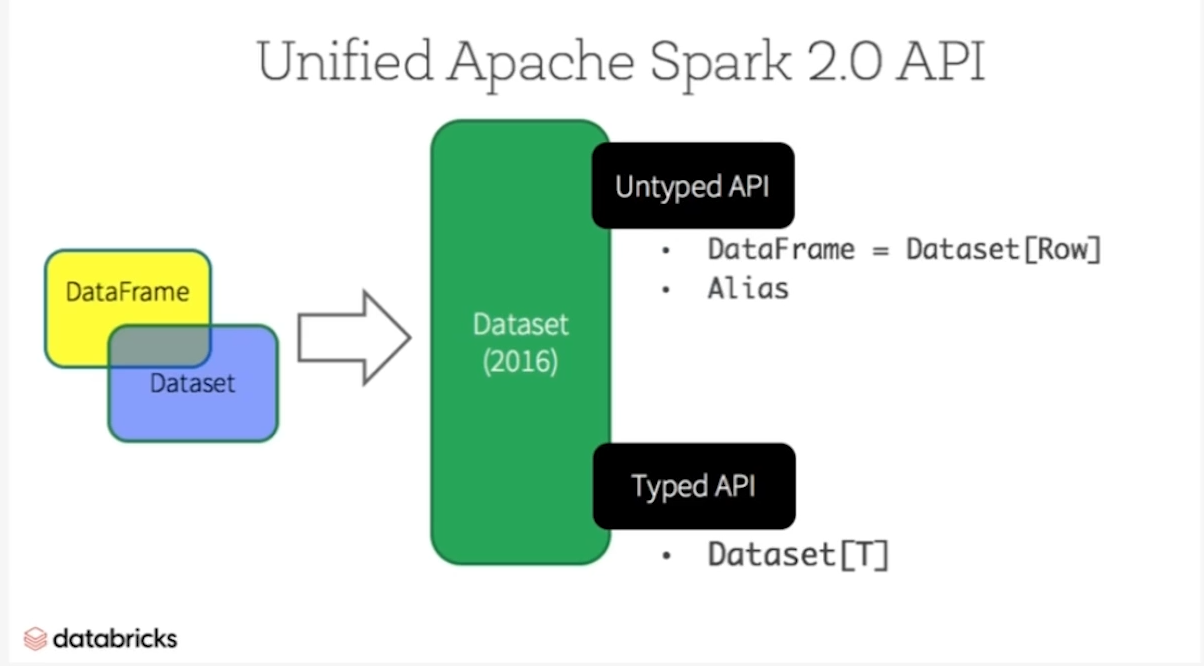
주요 특징
- Strongly Typed (Java and Scala): DataFrame is row of a Dataset JVM object
- Untyped (Python and R): most of the benefits available in the Dataset API are already available in the DataFrame API
요약
- Spark 1.6부터 도입
- 컴파일 시 타입 검사를 지원하는 강타입 구조
- Python에서는 제공되지 않음 (Scala/Java 전용)
- 내부적으로는 RDD와 유사하게 동작하되, Catalyst와 Tungsten 엔진의 이점도 같이 누림
- Tungsten 엔진
- Whole-stage Code Generation (WSCG) -> 연산 계획을 하나의 Java 함수로 통짜로 만들어버림
- Off-heap Memory Management -> JVM의 Heap 메모리 대신 Native 메모리 직접 관리
- Cache-aware Computing -> CPU 캐시에 잘 맞도록 메모리 배치 최적화
- Binary Memory Format
- Row-based → Columnar로 바뀜
- Arrow-like 포맷 사용 (내부적으로 Spark는 UnsafeRow 등 빠른 구조 사용)
- Tungsten 엔진
반응형